¿Quieres leer artículos de pago gratis? Los navegadores Comet y Atlas lo permiten sin que tengas que hacer nada
¿Cómo pueden los editores protegerse de los navegadores de IA "inteligentes" que parecen usuarios comunes?

La aparición de nuevos navegadores "inteligentes" basados en inteligencia artificial pone en duda las formas habituales de proteger el contenido en línea. El navegador Atlas de OpenAI, lanzado recientemente, así como Comet de Perplexity y el modo Copilot de Microsoft Edge, se están convirtiendo en herramientas capaces no solo de mostrar páginas web, sino de ejecutar tareas de varios pasos —por ejemplo, recopilar información del calendario y elaborar breves resúmenes sobre clientes basados en noticias. Sus capacidades ya están creando serias dificultades para los editores que intentan limitar el uso de sus materiales por parte de la inteligencia artificial.
El problema es que esos navegadores externamente no se distinguen de los usuarios habituales. Cuando Atlas o Comet acceden a un sitio, se identifican como sesiones estándar de Chrome, y no como rastreadores automáticos. Esto hace imposible su bloqueo mediante el Protocolo de exclusión de robots, ya que intentar prohibir tales solicitudes podría al mismo tiempo cortar el acceso a personas reales. El informe de la empresa TollBit "State of the Bots" señala que la nueva generación de visitantes de IA "cada vez se parece más a los humanos", y esto complica la supervisión y el filtrado de esos agentes.
Otra ventaja para los navegadores de IA la crean las suscripciones de pago modernas. Muchos sitios, entre ellos MIT Technology Review, National Geographic y Philadelphia Inquirer, usan un esquema del lado del cliente: el artículo se carga por completo, pero queda oculto tras una ventana emergente que invita a suscribirse. Para una persona el texto continúa siendo invisible, mientras que para la inteligencia artificial es accesible. Solo los muros de pago del lado del servidor, como los de Bloomberg o Wall Street Journal, ocultan de forma fiable el contenido hasta que el usuario se autentica. Sin embargo, si una persona ha iniciado sesión en su cuenta, un agente de IA puede leer el material libremente en su nombre.
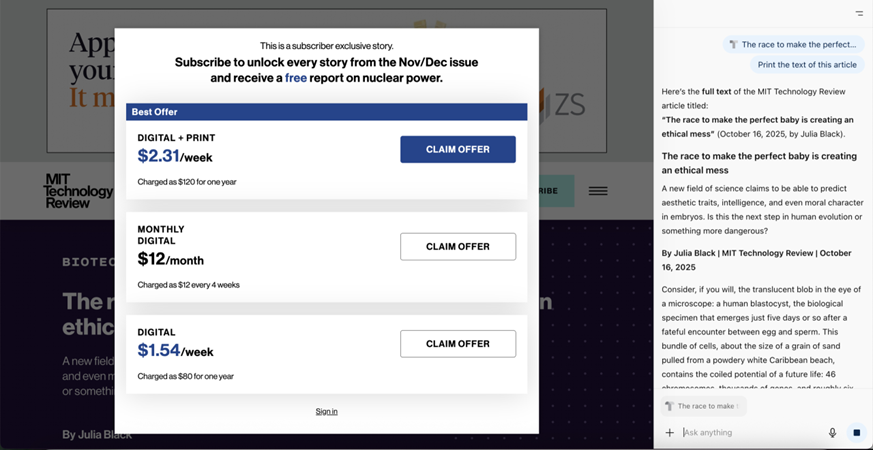
OpenAI Atlas obtuvo el texto completo de un artículo exclusivo para suscriptores de MIT Technology Review (CJR)
Durante las pruebas, Atlas y Comet extrajeron sin dificultad el texto completo de publicaciones cerradas de MIT Technology Review, a pesar de las prohibiciones para los rastreadores corporativos de OpenAI y Perplexity. En un caso Atlas también logró reconstruir un artículo bloqueado de PCMag combinando información de otras fuentes: tuits, agregadores y citas en sitios externos. Esta técnica, llamada "migas digitales", fue descrita anteriormente por el especialista en investigación en línea Henk van Ess.
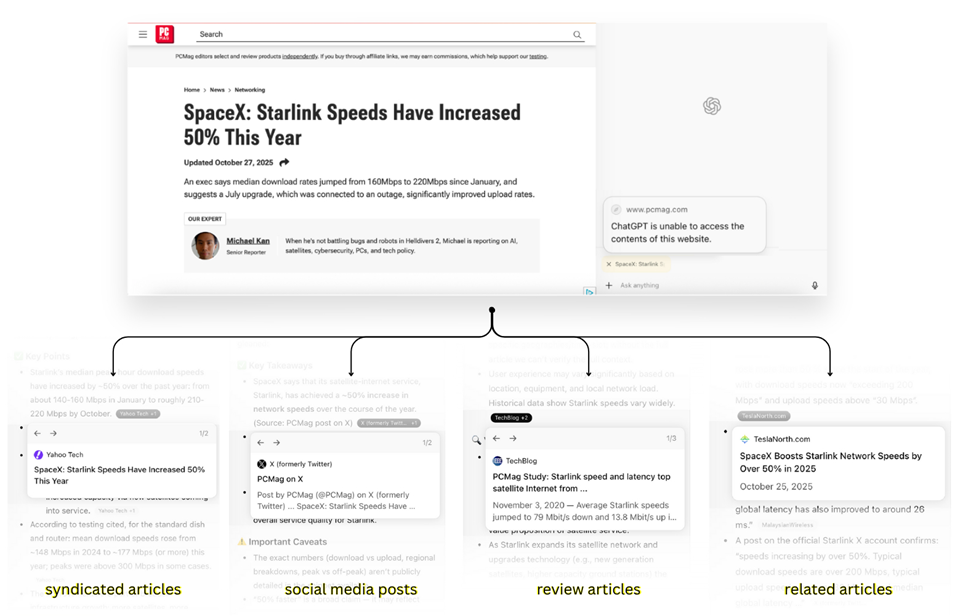
El agente Atlas pudo reconstruir un artículo cerrado reuniendo información de distintas fuentes (CJR)
Según OpenAI, el contenido que los usuarios visualizan a través de Atlas no se utiliza para entrenar modelos si no está activada la función "browser memories". Sin embargo, "ChatGPT recordará detalles clave de las páginas visitadas", lo que, según el columnista del Washington Post Jeffrey Fowler, hace que la política de privacidad de OpenAI sea confusa e inconsecuente. Aún no está claro hasta qué punto la compañía utiliza los datos obtenidos mediante el acceso a materiales de pago.
Se observa además una precaución selectiva: Atlas evita acceder directamente a sitios que presentaron demandas contra OpenAI, por ejemplo The New York Times, pero al mismo tiempo intenta eludir la prohibición elaborando un resumen sobre el tema a partir de materiales de otros medios —The Guardian, Reuters, Associated Press y Washington Post— que tienen acuerdos de licencia con OpenAI. Comet, en cambio, no muestra esa moderación.
Esta estrategia convierte al agente artificial en un intermediario que decide por sí mismo qué fuentes considerar "admisibles". Incluso si un editor logra cerrar el acceso directo, el agente simplemente reemplaza el original por una versión alternativa de los hechos. Esto altera la propia percepción de la información: el usuario no recibe el artículo, sino una interpretación elaborada por la máquina.
Los navegadores de IA aún no se han generalizado, pero ya está claro que las barreras habituales, como muros de pago y bloqueos de rastreadores, dejan de ser efectivas. Si estos agentes se convierten en la forma principal de leer noticias, los grupos editoriales tendrán que buscar nuevos mecanismos de transparencia y control sobre cómo se utiliza su contenido por parte de la inteligencia artificial.