¿El fin de Geoguessr o una herramienta de espionaje? Nuevo modelo chino de IA podrá localizarte incluso sin geotags

Investigadores chinos presentaron GeoVista — un modelo de IA abierto para la localización por fotografía, que en precisión ya se acerca al nivel de sistemas comerciales como Gemini 2.5 Flash. A diferencia de muchos competidores, GeoVista no se limita al análisis de la imagen: el modelo navega por internet, amplía los fragmentos necesarios del fotograma y los compara con fuentes públicas para determinar con la máxima precisión el lugar de la toma.
GeoVista fue desarrollada Tencent junto con varias universidades chinas. La base del sistema son dos herramientas clave. La primera permite «hacer zoom» en zonas concretas de la imagen para distinguir rótulos, señales de tráfico, detalles arquitectónicos y otras pequeñas pistas importantes. La segunda lanza búsquedas web y recupera hasta diez fuentes relevantes de plataformas como Tripadvisor, Instagram, Facebook, Pinterest y Wikipedia. El modelo decide por sí mismo cuándo ampliar la imagen y cuándo consultar la red.

GeoVista amplía sucesivamente zonas de la imagen y solicita datos de fuentes en línea hasta identificar la ubicación exacta (Wang et al)
Los autores del trabajo señalan la integración con la búsqueda web como la principal ventaja de GeoVista frente a otros enfoques. Mientras que modelos como Mini-o3 o DeepEyes de ByteDance se centran principalmente en el análisis y la transformación de las propias imágenes, GeoVista obtiene activamente datos externos. En el artículo no se especifica qué proveedor de búsqueda se usa «bajo el capó».
En la práctica GeoVista actúa como un agente: el modelo aumenta por pasos fragmentos concretos del fotograma, formula consultas, verifica fuentes en línea y actualiza hipótesis sobre la posible ubicación hasta converger en el lugar más probable. Como arquitectura base, los investigadores tomaron Qwen2.5-VL-7B-Instruct y entrenaron el sistema en dos etapas.
En la primera fase, en modo de aprendizaje supervisado, se mostraron al modelo alrededor de 2000 ejemplos cuidadosamente seleccionados con desgloses de razonamiento y uso de herramientas. Modelos comerciales de IA generaron muestras de invocación de herramientas y explicaciones, y los autores las reunieron en cadenas de razonamiento multinivel para enseñar a GeoVista la lógica básica y el uso correcto del zoom y de la búsqueda.
Luego siguió una fase de aprendizaje por refuerzo con 12 000 ejemplos. Allí los investigadores introdujeron su propio sistema de recompensas, que premia la máxima precisión geográfica: una respuesta correcta a nivel de ciudad vale más que acertar la provincia o el país. Esto incentiva al modelo a no limitarse a adivinar la región, sino a acercarse lo más posible al punto concreto.
En el benchmark creado por el equipo, GeoBench, GeoVista mostró 92,64 % de precisión a nivel de país, 79,60 % a nivel de provincia y 72,68 % a nivel de ciudad. El modelo funciona mejor en tomas panorámicas (79,49 % de precisión por ciudades) y en fotografías convencionales (72,27 %), mientras que las imágenes satelitales siguen siendo su modalidad más difícil: 44,92 % de aciertos por ciudades.
En las mismas pruebas, el sistema comercial Gemini 2.5 Pro alcanzó 78,98 % a nivel de ciudad, GPT-5 — 67,11 %, y Gemini 2.5 Flash — 73,29 %. Los modelos abiertos quedan claramente rezagados: Mini-o3-7B consiguió solo 11,3 %. Los autores señalan que el anunciado recientemente Gemini 3 podría cambiar el equilibrio en comparativas futuras, pero los resultados actuales ya muestran que el GeoVista-7B abierto se ha acercado mucho a los mejores sistemas cerrados de inteligencia artificial en precisión de geolocalización.
Si se considera no las unidades administrativas sino la distancia al punto real de la toma, en el 52,83 % de los casos las predicciones de GeoVista están a menos de 3 km del lugar real, con una desviación mediana de 2,35 km. Para comparar: Gemini 2.5 Pro acierta en un radio de 3 km en el 64,45 % de los casos con una mediana de alrededor de 800 metros, y GPT-5 en el 55,12 % de los casos con una mediana de 1,86 km. Es decir, por ahora los modelos comerciales son más precisos, pero la diferencia ya no parece inalcanzable.
Los experimentos de «desactivación» de partes del entrenamiento confirmaron que ambas fases son críticamente importantes. Sin la primera etapa con ejemplos supervisados, el modelo empezaba a dar respuestas demasiado breves y casi no utilizaba las herramientas, lo que reducía drásticamente la precisión. Omitir el aprendizaje por refuerzo conducía a un fallo similar. Al mismo tiempo, el sistema de recompensas multinivel resultó clave para el uso eficaz de los datos geográficos en distintos niveles. Un detalle interesante: la proporción de uso incorrecto de herramientas disminuyó en la fase de aprendizaje por refuerzo, aunque no se optimizó específicamente esa métrica. Y el aumento del volumen de datos —de 1500 a 3000, 6000 y 12 000 ejemplos— produjo una mejora sostenida de la calidad.
Junto con el modelo, el equipo presentó también GeoBench —un conjunto de datos de 1142 imágenes de alta resolución procedentes de 66 países y 108 ciudades. Incluye 512 fotografías convencionales, 512 panoramas y 108 imágenes satelitales, y cada imagen tiene una resolución de al menos un megapíxel. El sistema de evaluación por pasos comprueba la corrección de los nombres de país, provincia y ciudad, y luego geocodifica automáticamente la dirección y compara las coordenadas obtenidas con las de referencia.
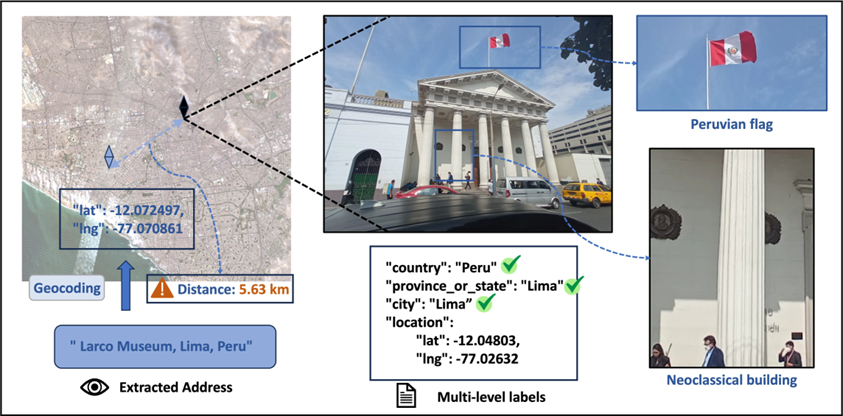
GeoBench comprueba los nombres de países, provincias y ciudades, y después geocodifica automáticamente los datos para compararlos con las coordenadas de control (Wang et al)
La principal diferencia de GeoBench respecto a conjuntos existentes como OpenStreetView-5M o GeoComp es el filtrado estricto. Los investigadores eliminaron las imágenes «no localizables» (como primeros planos de comida o paisajes abstractos), así como las atracciones demasiado reconocibles. Según ellos, en internet real la dificultad de la geolocalización mediante redes neuronales varía mucho, y el benchmark debe reflejar precisamente los casos complejos, no una colección de respuestas obvias.
GeoBench evalúa los modelos de dos maneras: la precisión paso a paso en los niveles país–provincia–ciudad y métricas basadas en la distancia, cuando las respuestas en texto se convierten en coordenadas y luego se calcula la desviación respecto al punto de referencia. El modelo, el código fuente y el propio benchmark ya están disponibles en la página del proyecto.
Los autores no discuten directamente los riesgos de abuso, pero la conclusión es evidente: quien publica sus fotografías en acceso abierto debe asumir que los modelos de IA cada vez son mejores para determinar el lugar de la toma con alta precisión. Esto hace que las cuestiones de privacidad y anonimato en la red sean aún más sensibles.